




HPSS: Celebrating 30 Years of Long-term Storage for Scientific Research
NERSC Contributions Include Improvements to Scalability, Reliability, and Usability
October 20, 2022
Contact: cscomms@lbl.gov
The 2022 HPSS User Forum will take place Oct. 25-28 in Houston, Texas.
Long-term data storage presents a unique challenge in scientific research. Not only do researchers need a reliable, scalable archive for their experimental and theoretical data, they need ready access to this data on an as-needed basis.
Thirty years ago, these challenges prompted the development of the High Performance Storage System (HPSS), a scalable long-term tape storage resource fostered by a collaboration of five Department of Energy (DOE) national laboratories (Lawrence Berkeley, Lawrence Livermore, Los Alamos, Oak Ridge, and Sandia) and industry partner IBM. The goal was to create an archiving resource that was high speed, massively scalable, and could leverage distributed hierarchical storage capacity management.
To date, this vision has met with broad-scale success. Since its introduction in 1992, HPSS has had a significant impact on scientific research and is currently in use at some 40 sites around the world, serving more than 4 exabytes of production archival storage data. In addition, many of its technological innovations have been adopted across not just the DOE national lab environment but by the data storage industry as well.
“It is a rare piece of software, and the fact that it’s been so successful for so long is amazing,” said Jason Hick, who was previously with the National Energy Research Scientific Computing Center (NERSC) as a senior storage engineer and lead of the Storage Systems Group but today is program manager for the Advanced Simulation and Computing program at Los Alamos National Laboratory. “People tend to say that software only lasts 10 years, and generally that is true. But here we are 30 years on.”
Hick has been involved with HPSS since 2001 and has navigated many of its iterations and upgrades. Some of the project’s key innovations include:

NERSC's HPSS StorageTek robotic tape storage unit at the Oakland Scientific Facility, circa 2009. Credit: Roy Kaltschmidt, Berkeley Lab
- Separating data commands and control traffic commands. The point of separating these two functions was to optimize parallelism, which was foundational to achieving parallelism and scalability.
- Distributed architecture. HPSS was one of the first to propose a distributed architecture, and the key in that was distributed transactions.
- Hierarchical storage management (HSM). “The whole idea is that it’s a tiered storage model, which is very hard to architect,” Hick said. “HPSS was the first long-term, highest scale, commercially successful system to implement HSM.”
- Network-based architecture. One of the proprietary successes of HPSS is the distributed network capability. This happened in the 1990s, when all high performance computing (HPC) went to a distributed design, which inherently means using the network, Hick noted.
- Remote procedure calls. HPSS was one of the first systems to recognize how to use remote procedure calls for distributed computing advantage.
The success of HPSS also stems from its collaborative development approach, which has allowed the project to meet the demands of evolving HPC platforms and performance needs over time, noted Shreyas Cholia, who leads the Integrated Data Systems group in the Scientific Data Division at Berkeley Lab and is a former computational systems engineer at NERSC. Shreyas began working with HPSS while interning at IBM in 1998-1999 and was involved in HPSS development efforts at NERSC from 2002-2008.
“Part of the reason HPSS has survived this long and been so impactful is because it was set up as a partnership between IBM and the national labs, which were very invested in the technology and have contributed a lot of time to developing the whole product,” Cholia said. “HPSS has been able to serve the needs of the national lab/HPC community as a tape archive that is sitting right next to the big systems. It is a way for people generating large scientific datasets to back things up in a cost-efficient manner.”

Interior panoramic of NERSC's HPSS storage silo at the Oakland Scientific Facility, circa 2010. Credit: Roy Kaltschmidt, Berkeley Lab
25 Years of HPSS at NERSC
NERSC was involved in the development of HPSS even before the system was installed at Berkeley Lab in 1997. Over the years, NERSC staff have spearheaded the design and implementation of numerous HPSS software, services, and upgrades.
For example, in 2009 the facility increased its HPSS storage capabilities to 59.9 petabytes — something that, at the time, was equivalent to all the music, videos or photos that could be stored on approximately 523,414 iPod classics — popular at the time — filled to capacity. Four years later, HPSS capabilities were instrumental in facilitating the Joint Genome Institute’s (JGI) Archive and Metadata Organizer (JAMO), a centralized data management system installed at NERSC to help JGI researchers deal more efficiently and effectively with the vast amounts of data yielded by increasingly complex bioinformatics projects.
In 2015, NERSC touted its expanded HPSS disk cache capacity, which was implemented in response to an analysis of user data utilization habits that found that the vast majority of data coming into NERSC at the time was accessed within the first 90 days. And in 2019, HPSS was central to a massive data transfer effort between Berkeley Lab’s Oakland Scientific Facility, where NERSC had been located since 2001, and the Berkeley Lab campus, where NERSC relocated in 2015. Some 43 years (120PB) of experimental and simulation data were stored on thousands of high performance tapes in Oakland, and that data was electronically transferred to new tape libraries at Berkeley Lab, a process that took about two years.
“HPSS is critical for scientists because they need a place where they can keep their data forever,” said Lisa Gerhardt, a big data architect in NERSC’s Data Analytics & Services Group who has overseen NERSC user support for HPSS since she came to NERSC in 2013. “We end up being the data repository for a lot of NERSC users, and that is what makes HPSS so valuable: you can put your data in there and be confident it will be there when you need it.”

Starting in 2015, NERSC’s Wayne Hurlbert (left; now retired) and Damian Hazen (right) oversaw the two-year transfer of NERSC's 120 petabyte data archive from the Oakland Scientific Facility to new tape libraries at Berkeley Lab. Credit: Peter DaSilva/Berkeley Lab
Reliability and Scalability
Today, the HPSS installation at NERSC supports more than 8,000 users with a broad range of scientific data storage needs. One reason for the ongoing popularity of HPSS is that it enables scientists to access high-volume, long-term data in a timely and efficient manner.
“Assigning value to a particular dataset is difficult, and putting data on tape means more data sets can be stored for a very long time using very little energy; tape media rests, unpowered, in the tape library until the data is needed,” said Kristy Kallback-Rose, group lead for the Storage Systems Group who joined NERSC in 2017. “When datasets are requested, robots get to work to automatically retrieve the correct tape media and load the data onto disk where the users can access it. Being part of the HPSS collaboration means NERSC and the other DOE labs make direct contributions and give guidance to continuously improve performance, efficiency, ease-of-use, and user interfaces for HPSS.”
Here are some of the many projects that rely on NERSC’s HPSS for long-term data storage and access:
- Decades of climate/earth system simulations, including many that contributed to IPCC reports and the Twentieth Century Reanalysis (20CR) project, an international effort to produce a comprehensive global atmospheric circulation dataset spanning the 20th century (over 30PB)
- All data produced by JGI, including raw sequence from sequencers, filtered/quality controlled sequence, mapped sequence, assembled genomes, transcriptomes, and sequences that have been through all the processing and are prepared in reference databases to be shared outward (over 20PB)
- Data and simulations for recent Cosmic Microwave Background (CMB) experiments. This includes data from 17 different telescopes, including BICEP/Keck and several experiments at the South Pole, such as the South Pole Telescope (over 5.5PB)
- All experiment data and associated simulation data from the Dark Energy Spectroscopic Instrument (DESI) experiment (over 5PB)
- All data from the tomography beamline at the Advanced Light Source at Berkeley Lab, dating back ten years (over 4PB)
“HPSS is a very heavily used resource and well liked by users even though it is a tape archive,” said Nick Balthaser, lead storage systems engineer at NERSC who has been with the Storage Systems Group since 2007. “At present we have almost 300 PB of user data stored in NERSC HPSS. It is really good for reanalysis of long-term data; the climate scientists love it because they get to store huge amounts of data and then pull it out and analyze it over and over using new analysis methods and algorithms.”
For example, the National Oceanic and Atmospheric Administration (NOAA) has had a long relationship with NERSC HPSS, said Chesley McColl, a senior associate scientist at NOAA’s Physical Sciences Laboratory who supports the NOAA-CIRES 20th Century Reanalysis (20CR) project. Having relied on NERSC HPSS for data storage for 14 years, McColl considers it an invaluable resource for researchers who want to access and analyze more than 200 years of NOAA weather and climate data on an as-needed basis.
“The way NERSC has set it up is extremely unique in that the facility’s science portal can access the HPSS directly,” she said. “From our perspective, having access to three different realizations of 20CR data at any time is really impressive. It is 25 petabytes of data that users can look at and compare just by going to the science portal.”
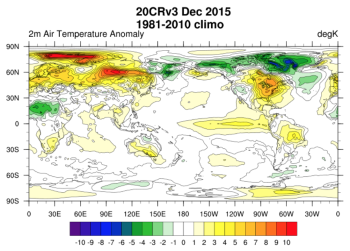
The NOAA-CIRES-DOE 20th Century Reanalysis V3 contains objectively analyzed 4D weather maps and their uncertainty from the early 19th century to the 21st century. Credit: NOAA
Another unique feature of NERSC HPSS is that it connects to Globus. “If you are having to download a massive amount of data and you don’t have the clock cycles to make sure everything is working, Globus can do that for you,” McColl said. “In addition, NERSC allows users to do multiple backups at the same time, which helps free up resources when you are in production mode.”
More User-Friendly User Interfaces
The system is also incredibly scalable, noted Francis Dequenne, who joined NERSC’s Storage Systems Group in 2021 after working 30 years with the European Centre for Medium-range Weather Forecasts (ECMWF), where he was instrumental in the design and architecture of ECMWF's Data Handling System and was also involved in beta testing several versions of HPSS.
One of the big differences between HPSS and commercially available storage systems is that HPSS was developed by people who are either users or very close to users of it, Dequenne noted. “So that means the requirements of it are not something that is dreamed up in a lab somewhere; rather, it is more the users saying ‘I need that,’ and then it is implemented,” he said. “Another big advantage of HPSS is that it is amazingly scalable. It was written that way from the start, and I don’t have any concerns that it will not continue to be very scalable for a very long time.”
Toward this end, NERSC is currently developing several enhancements to HPSS that are being designed primarily with users in mind – namely, more user-friendly user interfaces. At present, Melinda Jacobsen, an HPSS software developer in the Storage Systems Group, is focusing on the HSI/HTAR client interface and JSON support. HSI is a command-line interface for data storage and retrieval from HPSS; HTAR is a utility that manipulates HPSS-resident archives by writing files to, or retrieving files from, HPSS; and JSON (JavaScript Object Notation) is a data interchange format used for storing and transferring data, enabling machine interaction with software.
“My current focus is to address long-time interface limitations and restrictions that are affecting user access to HPSS,” Jacobsen said. For example, with HTAR, she is working to make it possible for users to handle unlimited file length and file size. She is also looking to add JSON output to HSI so that users will be able to more easily work with output from HSI for downstream applications.
“This helped realize my final goal: running the HSI and HTAR interfaces in a container environment, which we were able to do last spring,” she said. Brian Friesen, an HPC systems engineer in the Computational Systems Group at NERSC, is working to integrate this capability onto Perlmutter, which Jacobsen says will open up access for many NERSC users who use the system with upcoming container-based interactions.
“These three things – HTAR and HSI interfaces with JSON support in a container environment – led to probably our most exciting development area right now: running HTAR and HSI as a microservice on Perlmutter,” Jacobsen added. “This will offer a REST API for supporting programmatic access to HPSS. It will also eventually be incorporated into NERSC’s Superfacility API, which will open up even more HPSS access for users and support automated workflows.”
Looking back over the last 30 years and ahead to what is coming next, “the bottom line is a lot of HPSS has always been pushing the efforts of what a network can do, and we’ve always pushed those limits to add some scientific value,” Hick said. “It wasn’t just more data; it was higher fidelity simulation, new discoveries, and the processing of scientific data that hadn’t been done before.”
About NERSC and Berkeley Lab
The National Energy Research Scientific Computing Center (NERSC) is a U.S. Department of Energy Office of Science User Facility that serves as the primary high performance computing center for scientific research sponsored by the Office of Science. Located at Lawrence Berkeley National Laboratory, NERSC serves almost 10,000 scientists at national laboratories and universities researching a wide range of problems in climate, fusion energy, materials science, physics, chemistry, computational biology, and other disciplines. Berkeley Lab is a DOE national laboratory located in Berkeley, California. It conducts unclassified scientific research and is managed by the University of California for the U.S. Department of Energy. »Learn more about computing sciences at Berkeley Lab.