




Physics Data Processing at NERSC Dramatically Cuts Reconstruction Time
Demonstration Project Targets Nuclear Physics Data from STAR Experiment
February 6, 2018
By Kathy Kincade
Contact: cscomms@lbl.gov

Berkeley Lab's Jan Balewski, Mustafa Mustafa, and Jeff Porter pose in front of NERSC's Cori supercomputer.
In a recent demonstration project, physicists from Brookhaven National Laboratory (BNL) and Lawrence Berkeley National Laboratory (Berkeley Lab) used the Cori supercomputer at the National Energy Research Scientific Computing Center (NERSC) to reconstruct data collected from a nuclear physics experiment, an advance that could dramatically reduce the time it takes to make detailed data available for scientific discoveries.
The researchers reconstructed multiple datasets collected by the STAR (Solenoidal Tracker At RHIC) detector during particle collisions at the Relativistic Heavy Ion Collider (RHIC), a nuclear physics research facility at BNL. By running multiple computing jobs simultaneously on the allotted supercomputing cores, the team transformed raw data into “physics-ready” data at the petabyte scale in a fraction of the time it would have taken using in-house high-throughput computing resources—even with a two-way transcontinental journey via ESnet, the Department of Energy’s high-speed, high-performance data-sharing network that is managed by Berkeley Lab.
Preparing raw data for analysis typically takes many months, making it nearly impossible to provide such short-term responsiveness, according to Jérôme Lauret, a senior scientist at BNL and co-author on a paper outlining this work that was published in the Journal of Physics.
“This is a key usage model of high performance computing (HPC) for experimental data, demonstrating that researchers can get their raw data processing or simulation campaigns done in a few days or weeks at a critical time instead of spreading out over months on their own dedicated resources,” said Jeff Porter, a member of the data and analytics services team at NERSC and co-author on the Journal of Physics paper.
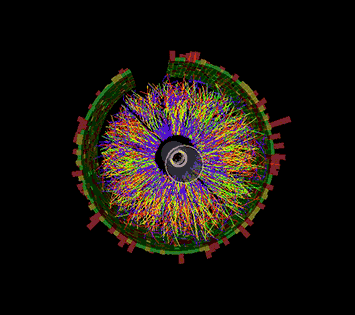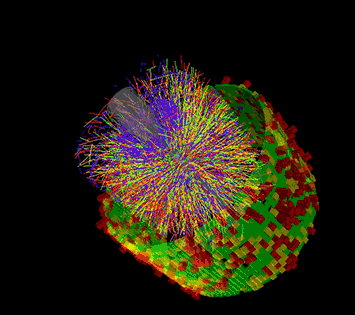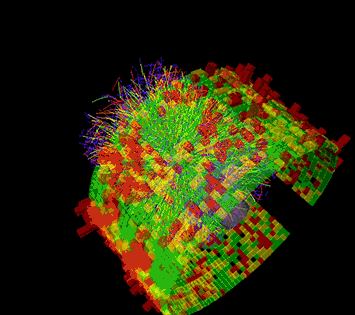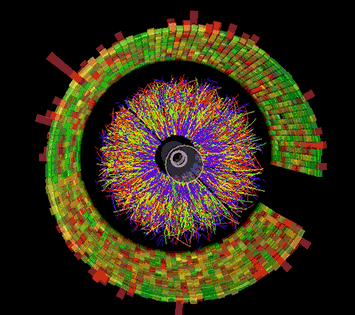
This animation shows a series of collision events at STAR, each with thousands of particle tracks and the signals registered as some of those particles strike various detector components. Image: Brookhaven National Laboratory
Billions of Data Points
The STAR experiment is a leader in the study of strongly interacting QCD matter that is generated in energetic heavy ion collisions. STAR consists of a large, complex set of detector systems that measure the thousands of particles produced in each collision event. Detailed analyses of billions of such collisions have enabled STAR scientists to make fundamental discoveries and measure the properties of the quark-gluon plasma. Since RHIC started running in the year 2000, this raw data processing, or reconstruction, has been carried out on dedicated computing resources at the RHIC and ATLAS Computing Facility (RACF) at BNL. High-throughput computing clusters crunch the data event by event and write out the coded details of each collision to a centralized mass storage space accessible to STAR physicists around the world.
In recent years, however, STAR datasets have reached billions of events, with data volumes at the multi-petabyte scale. The raw data signals collected by the detector electronics are processed using sophisticated pattern recognition algorithms to generate the higher-level datasets that are used for physics analysis. So the STAR computing team investigated the use of external resources to meet the demand for timely access to physics-ready data, ultimately turning to NERSC. Among other things, NERSC operates the PDSF cluster for the HEP/NP experiment community, which represents the second largest compute cluster available to the STAR collaboration.
A Processing Framework
Unlike the high-throughput computers at the RACF and PDSF, which analyze events one by one, HPC resources like those at NERSC break large problems into smaller tasks that can run in parallel. So the challenge was to parallelize the processing of STAR event data in a way that can scale out to run on large amounts of data with reproducible results.
The processing framework run at NERSC was built upon several core features. Shifter, a Linux container system developed at NERSC, provided a simple solution to the difficult problem of porting complex software to new computing systems and keep its expected behavior. Scalability was achieved by eliminating bottlenecks in accessing both the event data and experiment databases that record environmental changes—voltage, temperature, pressure and other detector conditions—during data taking. To do this, the workload was broken up into data chunks, sized to run on a single node onto which a snapshot of the STAR database could also be stored. Each node was then self-sufficient, allowing the work to automatically expand out to as many nodes as available without any direct intervention.
“Several technologies developed in-house at NERSC allowed us to build a highly fault-tolerant, multi-step, data-processing pipeline that could scale to practically unlimited number of nodes with the potential to dramatically fold the time it takes to process data for many experiments,” noted Mustafa Mustafa, a Berkeley Lab physicist who helped design the system.
Another challenge in migrating the task of raw data reconstruction to an HPC environment was getting the data from BNL in New York to NERSC in California and back. Both the input and output datasets are huge. The team started small with a proof-of-principle experiment—just a few hundred jobs—to see how their new workflow programs would perform. Colleagues at RACF, NERSC and ESnet—including Damian Hazen of NERSC and Eli Dart of ESnet—helped identify hardware issues and optimize the data transfer and the end-to-end workflow.
After fine-tuning their methods based on the initial tests, the team started scaling up, initially using 6,400 computing cores on Cori; in their most recent test they utilized 25,600 cores. The end-to-end efficiency of the entire process—the time the program was running (not sitting idle, waiting for computing resources) multiplied by the efficiency of using the allotted supercomputing slots and getting useful output all the way back to BNL—was 98 percent.
“This was a very successful large-scale data processing run on NERSC HPC,“ said Jan Balewski, a member of the data science engagement group at NERSC who worked on this project. “One that we can look to as a reference as we actively test alternative approaches to support scaling up the computing campaigns at NERSC by multiple physics experiments.”
About NERSC and Berkeley Lab
The National Energy Research Scientific Computing Center (NERSC) is a U.S. Department of Energy Office of Science User Facility that serves as the primary high performance computing center for scientific research sponsored by the Office of Science. Located at Lawrence Berkeley National Laboratory, NERSC serves almost 10,000 scientists at national laboratories and universities researching a wide range of problems in climate, fusion energy, materials science, physics, chemistry, computational biology, and other disciplines. Berkeley Lab is a DOE national laboratory located in Berkeley, California. It conducts unclassified scientific research and is managed by the University of California for the U.S. Department of Energy. »Learn more about computing sciences at Berkeley Lab.